
อากาศร้อนๆ คิดอะไรเรื่อยเปื่อย (อีกแล้ว)
ผมว่า ใครหลายๆคน น่าจะเคยเห็นกราฟนี้กันใช่ไหมครับ
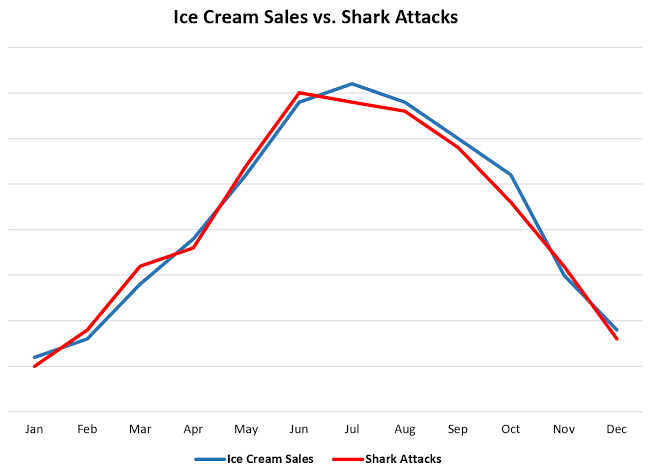
เมื่อ ยอดขายไอศกรีม พุ่งสูงขึ้น สถิติคนโดนฉลามกัด ก็พุ่งสูงขึ้นในทิศทางเดียวกัน
หรือ...การกินไอศกรีม ทำให้ฉลามโกรธ
ถ้าเรามองแค่ตัวเลขผิวเผิน เราก็อาจจะสรุปแบบกำปั้นทุบดินได้แบบนั้นแหละครับ รวมไปถึงว่า ถ้าอยากลดคนโดนฉลามกัด ให้สั่งห้ามขายไอศกรีมซะ!
แต่...ฟังดูไร้สาระใช่ไหมครับ?
เพราะความจริง มันมีข้อมูลแฝง ที่เรียกว่า "หน้าร้อน" อยู่ต่างหาก
อากาศร้อนทำให้คนกินไอศกรีมเยอะขึ้น และ อากาศร้อนก็ทำให้คนไปเล่นน้ำทะเลเยอะขึ้น โอกาสเจอฉลามก็เลยสูงขึ้นตามไปด้วย แต่ไม่ได้หมายความว่า ไอศกรีมเป็นต้นเหตุให้ฉลามดุร้ายขึ้นแต่อย่างใดเลยครับ
ซึ่งในโลกของ Data เราเรียกสิ่งนี้ว่า Spurious Correlation หรือตามที่จั่วหัวเลยครับ ความสัมพันธ์จอมปลอม นั่นเอง แบบนี้ ถือว่าอันตรายมากเลยใช่ไหมครับ เพราะจริงๆแล้ว เราอาจแค่ตีความผิด หรือจริงๆ อาจจะมีปัจจัยอะไรที่ทับซ้อนอยู่ก็เป็นได้ครับ
เดี๋ยวจะเกริ่นยาวไป เรามายกตัวอย่างให้เห็นภาพชัดขึ้นกันดีกว่าครับ
1. Survivorship Bias: เมื่อข้อมูลที่ หายไป คือ คำตอบ ที่แท้จริง
บทเรียนคลาสสิคนี้ มาจากสงครามโลกครั้งที่ 2 ครับ เมื่อกองทัพสหรัฐฯ ได้ข้อมูลจากเครื่องบินรบที่รอดกลับมาจากภารกิจ แล้วพบว่าตัวเครื่องและปีกของเครื่องบินลำนี้ เต็มไปด้วยรูพรุนจากกระสุนครับ

สัญชาตญาณแรกของกองทัพ (หรืออาจจะเราๆ เอง) มองว่า เราต้องเสริมเกราะตรงปีกกับตัวเครื่องให้หนาขึ้น ใช่ไหมครับ
แต่ Abraham Wald นักสถิติจากกลุ่ม Statistical Research Group (SRG) ได้โต้แย้งว่า จริงๆแล้ว เราต้องเสริมเกราะในจุดที่ไม่มีรอยกระสุนต่างหาก"
ลองนึกดูดีๆ ก็สมเหตุสมผลใช่ไหมครับ ถ้าเครื่องบินที่มีรอยกระสุนตรงปีกแต่ยังบินกลับมาให้เราเก็บข้อมูลได้ แปลว่าจุดนั้นไม่ใช่จุดที่ sensitive ต่อการถูกสอยร่วง แต่กลับกัน ถ้าเป็นจุดอื่น เครื่องบินลำนั้นๆ ที่คงไม่มีโอกาสได้กลับมาให้เราเห็นข้อมูล จริงไหมครับ เพราะมันร่วงไปหมดแล้วตั้งแต่อยู่ในสมรภูมิ
นี่คือ Survivorship Bias ที่สอนเราว่า ข้อมูลที่เราเห็นตรงหน้าอาจไม่ใช่ภาพรวมทั้งหมด ถ้าเราตัดสินใจจากแค่ ผู้รอดชีวิต (ข้อมูลที่เหลืออยู่) โดยลืมมอง ผู้ที่จากไป (ข้อมูลที่ขาดหาย) เราอาจจะแก้ปัญหาผิดจุดไปคนละทิศเลยครับ
เหมือนแบรนด์ที่ทำ Survey เฉพาะลูกค้าที่ยังใช้อยู่ แต่ลืมถามลูกค้าที่เลิกใช้ไปแล้ว ว่าอะไรทำให้ลูกค้าเหล่านั้นเลิกใช้ไปนั่นเองครับ
2. Zillow: เมื่อเชื่อมั่นในอัลกอริทึม จนขาดทุน 3 หมื่นล้าน

ถ้าขยับมาที่โลกธุรกิจกันบ้าง คงต้องยกตัวอย่าง Zillow แพลตฟอร์มอสังหาริมทรัพย์ขนาดใหญ่ในอเมริกาครับ
Zillow เนี่ย เคยพยายามใช้ระบบที่ชื่อว่า Zestimate ซึ่งเป็นอัลกอริทึมประเมินราคาบ้านจาก Data จำนวนมหาศาล เพื่อเอามาขายต่อ โดยเจ้าอัลกอริทึมที่ว่าเนี่ย ก็จะช่วยแนะนำให้ซื้อบ้านที่ ราคาดี มีโอกาสทำกำไรสูง โดยที่ทาง Zillow แทบไม่ได้ส่งคนไปดูสภาพบ้านจริงเลย
หลายคนอาจมองว่า ปัญหามีแน่ๆ ใช่ไหมครับ โดยอาจพุ่งเป้าไปที่คำถามว่า "ถ้าบ้านจริงมันโทรมกว่าในรูปล่ะ?"
แต่...ถึงไม่ใช่ ก็ใกล้เคียงครับ
แม้ว่าเรื่องการประเมินความทรุดโทรม ทาง Zillow เองก็มีประเมินเผื่อไว้อยู่แล้ว แต่สิ่งที่ Data บอกไม่ได้คือ "บริบทที่เปลี่ยนไป" ครับ ในช่วงปี 2021 (ช่วงหลังการระบาดของ Covid-19 ระลอกแรก) ทำให้ค่าแรงช่างและวัสดุก่อสร้างพุ่งสูงขึ้นอย่างมากจากปัญหา Supply Chain ทำให้งบปรับปรุงบ้านบานปลาย และพอผนวกเข้ากับสภาพบ้านจริงที่ทรุดโทรมกว่าในรูปจนอัลกอริทึมประเมินพลาดอีก
เท่ากับว่า Zillow ซื้อมาราคาแพงเกินจริง และพอเจอค่าใช้จ่ายต่างๆ จะให้ขายถูกก็คงไม่ได้
ใช่ครับ...ราคาที่เขยิบขึ้นไปทำให้ขายไม่ออก สุดท้ายต้องปิดแผนก Zillow Offers ไปเมื่อช่วงปลายปี 2021 และ ขาดทุนไปกว่า 880 ล้านเหรียญสหรัฐ (หากเทียบเรตเงินช่วงนั้นจะอยู่ที่ประมาณ 2.8 - 3 หมื่นล้านบาท) ภายในปีเดียวครับ
บทเรียนจาก Zillow ทำให้เราเห็นว่าบางที ข้อมูล ก็เป็นเหมือน ไฟฉาย ครับ และเมื่อส่องไปตรงไหน (Data Visualization) มันก็สว่างแค่ตรงนั้น มันไม่ใช่คำตอบหรือความเป็นจริงทั้งหมดครับ
แต่ถ้าใครมองว่ามันผิดเองที่เชื่อใจ AI มากไป งั้นต้องลองมาดูเรื่องต่อไปนี้ครับ
3. Simpson's Paradox: เมื่อผลรวมของข้อมูล กลับ "สวนทาง"
เหตุการณ์นี้คือ การที่ข้อมูลในกลุ่มย่อยบอกอย่างหนึ่ง แต่พอเอามารวมกันปุ๊บ ผลลัพธ์กลับกลายเป็นอีกอย่างเฉย แค่ได้ยินก็งงแล้วใช่ไหมล่ะครับ
เคสที่ดังที่สุด คือการรับสมัครนักศึกษาของ UC Berkeley ในปี 1973 ครับ ข้อมูลบอกว่า มีจำนวนนักศึกษาที่ได้รับตอบรับ 44% และเพศหญิง 35% เมื่อมองจากภาพรวม เราก็จะเห็นว่าทางมหาวิทยาลัย เน้นรับ ผู้ชาย มากกว่า ผู้หญิง ถูกไหมครับ (ใช่แหละ เพราะทางมหาวิทยาลัยเกือบถูกฟ้องเรื่องการเหยียดเพศเพราะข้อมูลนี้เลย)
แต่ทีนี้ พอเจาะลงไปวิเคราะห์รายคณะ กลับพบว่า ในเกือบทุกคณะ ผู้หญิงมีอัตราการตอบรับเข้าเรียนสูงกว่าผู้ชายด้วยซ้ำ
เอ้า! ยังไงล่ะทีนี้... คำตอบอยู่ที่ พฤติกรรมการเลือก ครับ ผู้หญิงส่วนใหญ่มักจะสมัครเข้าเรียนในคณะที่มีการแข่งขันสูงมากและมีอัตราการรับต่ำ (เช่น มนุษยศาสตร์) ในขณะที่ผู้ชายมักจะสมัครในคณะที่รับคนเยอะและคู่แข่งน้อยกว่า ผลรวมเลยออกมาบิดเบือนไปครับ
เคสนี้ก็เลยสอนเราว่า การมองแค่ ค่าเฉลี่ย แต่ไม่ได้ดูข้อมูลรายย่อย (Segment) อาจทำให้เราเข้าใจผิดได้ง่ายๆ เลยครับ

ถ้าเรามาดูรูปข้างบนนี้จะยิ่งเห็นชัดขึ้นครับ ภาพรวม (รูปซ้ายมือ) เราจะเห็นว่ายิ่งอายุงานยิ่งเยอะ เงินเดือนกลับดูลดลงใช่ไหมครับ แต่ถ้าเราแยกดูส่วนย่อยๆของข้อมูล (รูปขวามือ) เราก็จะเห็นว่า อ้อ...จริงๆ แล้ว มันไม่ได้ลดลงเลยนะ
4. Cherry Picking: ถ้าทรมานข้อมูลหนักพอ มันจะยอมสารภาพทุกอย่าง
เวลาเราเก็บเชอรี่ เราจะเลือกเก็บใช่ไหมครับ เราไม่เลือกผลที่ยังไม่สุก เราไม่เลือกผลที่สุกงอม และเราก็ไม่เลือผลที่หนอนเจาะ
ในโลกยุคที่อะไรๆ ก็ Data ก็เหมือนกันครับ เรามักเลือกเด็ดข้อมูลเฉพาะส่วนที่สนับสนุนความเชื่อของตัวเองมาโชว์ครับ
คล้ายๆกับการที่มีคนเชียร์หุ้นตัวนึงที่กราฟพุ่งปรู๊ดปร๊าดในช่วง 3 เดือนที่ผ่านมา
โอ้โห...น่าโดดเข้าไปแจมด้วยเลยใช่ไหมครับ
แต่ถ้าเราลองซูมออกมาดูภาพรวม 5 ปี เราอาจพบว่ามันรูดลงมาตลอด และไอ้ที่ขึ้นมานั้นเป็นแค่ช่วงสั้นๆ เท่านั้นเอง
การจงใจตัดช่วงเวลา (Sorting) หรือเลือกเฉพาะตัวอย่างที่ดูดีมานำเสนอ คือวิธีการที่คนเอา Data มาใช้ ปั่น ความรู้สึกเราได้แนบเนียนที่สุด เหมือนคำกล่าวของ Darrell Huff ผู้เขียนหนังสือ How to Lie with Statistics ที่ว่า
"ถ้าคุณทรมานข้อมูลหนักพอ มันจะยอมสารภาพทุกอย่างที่คุณอยากได้ยิน"
ดังนั้นเวลาใครเอาตัวเลขสวยๆ มาโชว์เรา เราคงต้องเคี่ยวข้อมูลให้หนักแล้วล่ะครับว่า ข้อมูลส่วนที่เหลือหน้าตาเป็นยังไง
เอาล่ะครับ...ถ้าอยากรู้ว่า ถ้าเราเคี่ยวข้อมูลมากพอ มันจะสารภาพทุกอย่าง จริงหรือไม่ ผมอยากให้ลองฟังเคสต่อไปนี้ครับ
5. Target: เกือบพัง เพราะรู้มาก (จาก Data)
เคสนี้แสดงให้เห็นว่า Data แม่นจนขนลุกครับ (แถมยังมาก่อนยุค AI จะบูมเสียด้วยซ้ำ ประมาณปี 2012) Target เคยใช้ข้อมูลวิเคราะห์พฤติกรรมการซื้อจนพบว่า ผู้หญิงที่เริ่มเปลี่ยนมาซื้อโลชั่นไร้กลิ่น วิตามินเสริมบางชนิด และสำลีก้อนในปริมาณมาก มีโอกาสสูงมากที่จะ กำลังตั้งครรภ์
พวกเขาจึงส่งคูปองสินค้าเด็กไปให้ลูกค้าสาวรายหนึ่งตามการคาดการณ์

ปรากฏว่าพ่อของลูกค้าสาวคนนั้นโกรธมากและไปโวยวายที่สาขาว่า
"ลูกสาวผมยังเรียนอยู่ คุณส่งคูปองพวกนี้มาส่งเสริมให้เด็กใจแตกเหรอ!"
แต่...ไม่กี่วันให้หลัง พ่อคนนั้นต้องกลับมาขอโทษ เพราะลูกสาวเขาท้องจริงๆ ครับ
จากนั้น Target ก็ได้ปรับกลยุทธ์ใหม่เล็กน้อยครับ โดยการส่งคูปองสินค้าเด็กปะปนไปกับสินค้าอื่นๆ ที่อาจไม่เกี่ยวข้องกันเลย (เช่น เครื่องตัดหญ้า) เพื่อให้ลูกค้ารู้สึกว่า "อ๋อ เป็นคูปองสุ่มๆ มา" ไม่ได้มองว่าถูกจับจ้องและรุกล้ำมากเกินไปครับ
เล่าไปซะไกลเลย เพราะจริงๆ แล้ว ผมอยากพูดถึง "ความสัมพันธ์จอมปลอม" จากข้อมูลที่ Correlation but NOT Causation เฉยๆ
แต่ก็อย่างว่านะครับ เราอยู่ในยุคของ Data ยุคของ Attention Economy อะไรๆ ที่เขาใช้ข้อมูลดึงดูดความสนใจเราได้ เขาทำกันหมดแหละ
อย่าลืมครับว่า Data มันแค่ไฟฉาย ฉายไปที่ไหนตรงนั้นก็จะชัด เราเลยอาจต้องเคี่ยวข้อมูลให้ลึกพอให้มันตอบทุกอย่างที่เราต้องการครับ
#data #spuriouscorrelation #failure
Comments