
Ruby's duckie ✨ คั้บ ที่กำลังฝึกวิเคราะห์ข้อมูลให้เก่งๆ อยู่เด้ออออ และๆๆๆ มาใน tag ใหม่ !! upskill
วันนี้มีโอกาสได้ศึกษาทางคลินิกเกี่ยวกับโรค NCDs มันเกิดขึ้นเพราะตัวเราเองทั้งนั้นนเลย เพราะเรามีนิสัยและพฤติกรรมการดำเนินชีวิตที่ไม่เหมาะสมสะสมเป็นเวลานาน เช่นกินอาหารที่ไม่เลือก หรือง่ายๆ กินของที่ไม่มีประโยขน์นั้นเเหละ ก็มีอร่อยเนาะ เข้าใจได้ 555+? แล้วนั่นทำให้เกิด metabolic syndrome เลย โถ่ววว
ดังนั้นจึงมีความสนใจว่า เอ้ะ ถ้ามีผลิตภัณฑ์เสริมอาหารมาช่วยลดความเสี่ยงในการเกิดก็คงจะดีเลยละ เลยได้ขอให้ท่าน Gemini ช่วย Mock data ขึ้นมาให้ฝึกกลยุทธ์ในการหา Metabolic-Insight จากการศึกษาประสิทธิภาพเชิงคลินิกของผลิตภัณฑ์เสริมอาหาร Dietary Supplement vs. interventoin (n = 200) เพื่อดูการเปลี่ยนแปลงขององค์ประกอบร่างกายและค่าเคมีในเลือดหลังจาก 3 เดือน
The Challenge: จากตัวเลขในห้องแล็บ สู่ Insights ที่จับต้องได้
dataset ที่ให้ท่าน gemini mockup ขึ้นมาให้ฝึก เท่ไม่หยอกกก อิอิ : dataset
1. Data Scope & Structure
- Metabolic Study : EDA and Insight
- About Dataset Utillize 12 clinical features focus on metabolic health. it tracks the physiological changes in 200 individuals to determine if the intervention (supplement) produces a statistically significant improvement compared to the control (placebo).
- study population : n = 200 (intervention vs control 1:1)
- time frame : 12 months (Capture baseline vs. end-point data).
- Objective: to evaluate the effecacy of the supplement on metabolic makers.
- tool : R programming.
2. Data Structure in 12 clinical featuer
Colume Descriptions :
id คือ รหัสประจำตัวของผู้เข้าร่วมวิจัย
group คือ กลุ่มที่แต่ละ ID โดนสุ่มว่าจะได้อยู่กลุ่มไหน ประกอบด้วย Supplement และ Control
visit คือ แต่ละทำการ follow up เริ่มตั้งแต่ baseline ไป end-point เลย
age อายุ ระหว่าง 30 – 65 ปี
gender เพศ
height_cm ส่วนสูง หน่วยเป็น cm.
weight_kg น้ำหนัก หน่อวยเป็น kg.
body_fat_pct เปอร์เซนต์ไขมันในร่างกาย
lean_kg มวลกล้าวเนื้อ หน่วยเป็น kg.
bmr ค่าการเผาพลาญของร่างกาย
hb_a1c ค่าน้ำตาลในเลือดสะสม
ldl ค่าไขมันดี
3.Data Preparation & Cleaning
3.1 import library
install.packages(c("gtsummary", "flextable", "gt"))
install.packages("openxlsx")
library(dplyr)
library(tidyverse)
library(ggplot2)
library(gtsummary)
library(flextable)
library(gt)
library(patchwork)
library(rstatix)
library(openxlsx)
3.2 EDA & Clean Data
# 1. check data structure
glimpse(df)
names(df)
# 2. ตรวจสอบจำนวนค่าว่าง (NA) ในแต่ละคอลัมน์
colSums(is.na(df))
# 2. Imputation NA
df_clean <- df %>%
# Convert to Factors
mutate(across(c(group, visit, gender), as.factor)
) %>%
mutate(
weight_kg = ifelse(is.na(weight_kg),
mean(weight_kg, na.rm = TRUE), weight_kg),
hb_a1c = ifelse(is.na(hb_a1c),
mean(hb_a1c, na.rm = TRUE), hb_a1c)
) %>%
ungroup() %>%
# BMI calculated
mutate(
bmi = weight_kg / (height_cm / 100)**2
)
# Check NulL again !
colSums(is.na(df_clean))
จากการ check คร่าวๆ จะพอรู้แล้วละว่ามีค่าว่าง (NA) อยู่ในข้อมูลของเรา ดังนั้นเพื่อเป็นการเก็บข้อมูลไว้ เลยตัดสินใจ data imputation ด้วยการหาค่าเฉลี่ยของ column นั้นๆ และไหนก็ %>% ไปแล้ว เลยทำการ set บาง feature เป็น factor ไปด้วยเลย รวมถึงหา bmi รอเลยย เท่านี้พอข้อมูลของเราก็สะอาดแล้วว แต่ยังใช้ไม่เลยซะทีเดียว ต้องทำการดูก่อนว่าข้อมูลเรามีการกระจายตัวแบบปกติไหม ดูการกระจายตัวของข้อมูลแบบไวๆ เลย คงไม่พ้นเอาข้อมูลมา plot graph ดู !!! เริ่มเลย
3.3 Data Normal Distribution
เราจะลองดูที่ BMI และ HbA1C ของข้อมูลเพราะเปรียบเสมือนตัวแทนที่ส่งผลต่อระบบ metabolism ทั้งหมด
เกริ่นก่อนอีกนิด ! การที่เราดูการกระจายตัวของข้อมูงเป็นการดูว่าข้อมูลของเรา “ปกติ” หรือ “เบ้” และมีค่าที่น่าสงสัยหรือไม่ เพราะหากข้อมูลของเราไม่ปกติ ผลลัพธ์ที่ได้ก็อาจจะทำให้ตีความผิดไปเลยก้ได้ (ซึ่งจริงๆ มีวิธีการจัดการ หรือ stat test กับพวกข้อมูลที่เป็น non parametric อยู่)
เราสาสมารถใช้ base R ดูการกระจายตัวแบบเร็วๆ ได้เลย ทำตัวอย่างให้ดูในส่วนของ bmi
# Check Normalization
hist(df_clean$bmi,
main = "Normolization of BMI",
xlab = "kb/m2")
4. Discovering Insights from the Data.
4.1 Baseline Characturistics (Mean ± SD)
เป็นการดูว่าจุดเริ่มต้นของเรา แฟร์ไหม ? หรือง่ายๆคือ ทั้ง 2 กลุ่มเนี่ยมีความแตกต่างกันมากน้อยแค่ไหน ก่อนที่เราจะเอาไปวิเคราะห์ ซึ่งใน project นี้ Ruby ขอนำเสนอ library ต่อไปนี้ ซึ่ง add ต่อไปได้เลย หรือจากด้านบน install แล้วก็ไม่ต้องติดตั้งเพิ่ม
library(gtsummary)
library(flextable)
library(gt)
ต่อมาเรามาทำการเลือก หรือจัดการข้อมูลก่อนเลยว่าเราจะเอาอะไรบ้างไปใส่ในตาราง จาก code จะเห็นเราเริ่ม filter ของ baseline ก่อนเพื่อดูว่า เอ๊ะ จุดเริ่มต้นเราต่างกันไหมนะ
tb_baseline <- df_clean %>%
filter(visit == "Baseline") %>%
select(id, group, age, gender, weight_kg, body_fat_pct, lean_kg, bmr,
hb_a1c, ldl, bmi)
ต่อมาเป็นการสร้างตารางแล้วละ สามารถอ่าน document ได้เลยที่ : Document
ttb1 <- tb_baseline %>%
select(-id) %>%
tbl_summary(
by = group,
label = list(
age ~ "Age (years)",
weight_kg ~ "Weight (kg)",
hb_a1c ~ "HbA1C (%)",
ldl ~ "LDL (mg/dl)",
body_fat_pct ~ "% Body Fat",
lean_kg ~ "Muscle Lean (kg)",
bmr ~ "BMR",
bmi ~ "BMI (kg/m2)"
), statistic = list(
all_continuous() ~ "{mean} ({sd})", # show mean
all_categorical() ~ "{n} ({p}%)" # show N (%)
),
digits = list(all_continuous() ~ 1),
missing = "no"
) %>%
## เพิ่มส่วนของ p -value
add_p(
test = list(
all_continuous() ~ "t.test",
all_categorical() ~ "chisq.test"
)
) %>%
## add column Overall
add_overall() %>%
modify_header(label = "**Variable**") %>%
modify_spanning_header(c("stat_1","stat_2") ~ "**group**") %>%
bold_labels()
print(tb1)
ตารางที่เราจะได้ (table 1) จะะดูสะอาด modern สามารถเอาไปตีพิมพ์ได้เลย จะเห็นว่าจะมีทั้งคอลัม overall ให้เราอีกด้วย พร้อมทั้งเราได้ทำการ add_p() ไปแล้วด้วยเลยว่าทั้งสองกลุ่มมีจุดเริ่มต้นที่แตกต่างกันไหม โดยใช้ stat ตัว t.test ในการวิเคราะห์ (ปล. ถ้าข้อมูลกระจายตัวไม่ปกติจะใช้อีกอัน คือ Wilcoxon test) 🤯
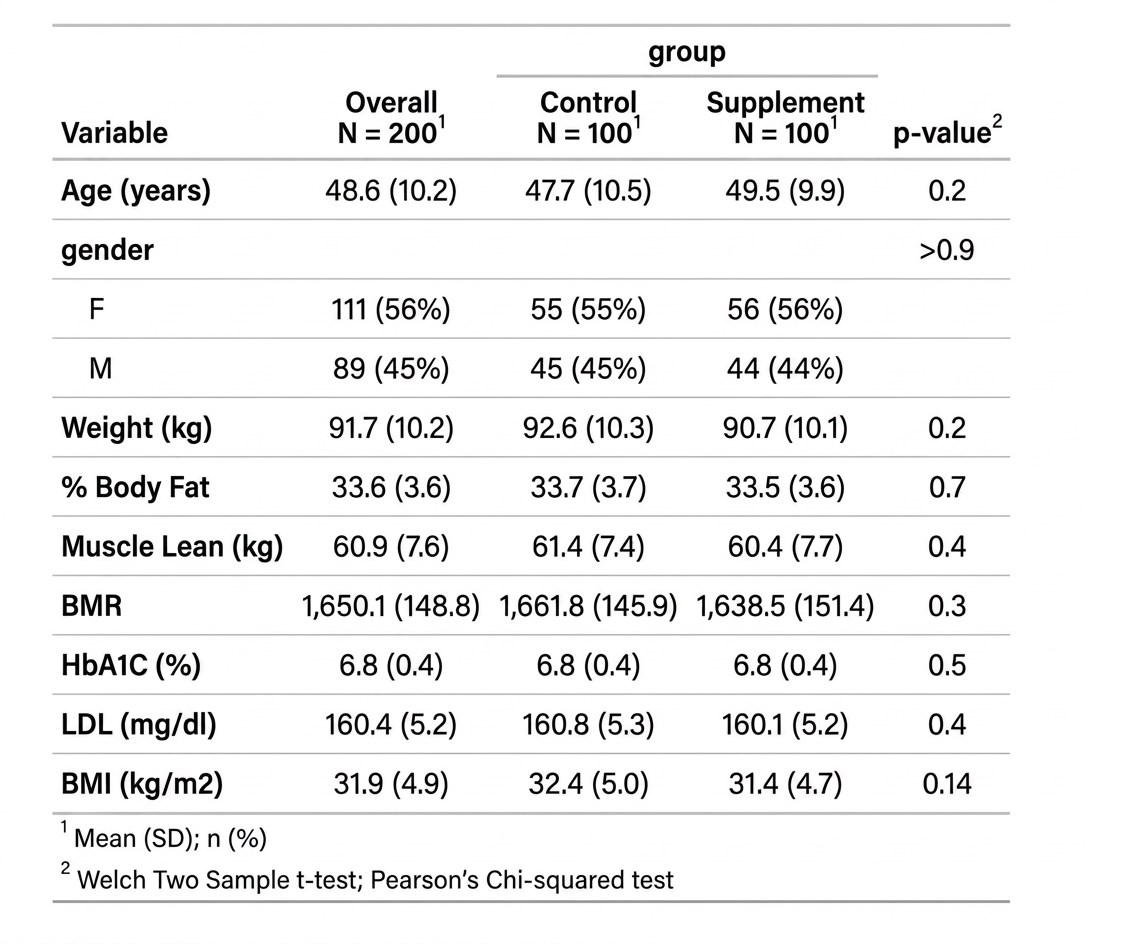 table 1: Comparison baseline characteristic
table 1: Comparison baseline characteristic
4.2 Effectiveness Insight with Dalte Analysis
วิเคราะห์การเปลี่ยนแปลงของผู้ที่เข้าร่วมวิจัยว่าตลอดเวลาที่เข้าร่วมการวิจัย ติดตามผลเนี่ย ร่างกายมีการเปลี่ยนแปลงอะไรบ้าง ? ใครดีกว่ากัน ? โดยเราทำการเปลี่ยนตัวแปรใน visit ก่อน เพื่อให้ R หาตัวแปรเหล่านี้ง่ายๆ (ไม่มี white space)
df_prepared <- df_clean %>%
mutate(visit_clean = case_when(
visit == "Baseline" ~ "M00",
visit == "Day 90" ~ "M03",
visit == "6 Months" ~ "M06",
visit == "9 Months" ~ "M09",
visit == "12 Months" ~ "M12",
TRUE ~ visit
))
# ตรวจสอบว่าถูกเปลี่ยนครบหมดไหม
table(df_prepared$visit_clean, df_prepared$group)
จากนั้นเราเริ่มต้นด้วยการคำนวนหา % การเปลี่ยนแปลง โดยสูตรการหา % Delta Change = ((post-pre)/pre) * 100 ด้วยการสร้าง function () ขึ้นมาใช้เอง เรามาดู full function ก่อนดีกว่า เดียวจะอธิบายแต่ละส่วนว่าทำงานยังไง ง่ายนิดเดียว ที่เหลือยากหมดดด 55555+ 🙂↕️🚀
plot_trajectory_pct <- function(var, ylab) {
# 1. คำนวณ % change โดยการใช้สูตรดึงค่าวันแรก (M00) ของแต่ละ id
df_pct <- df_prepared %>%
filter(visit_clean %in% c("M00", "M03", "M06", "M09", "M12")) %>%
group_by(id, group) %>%
arrange(visit_clean) %>%
mutate(
baseline_val = first(.data[[var]]), ## .data[[var]] = df_prepared$var
# ใช้สูตรปกติคำนวณ
pct_change = ((.data[[var]] - baseline_val) / baseline_val) * 100
) %>%
ungroup()
# 2. สรุปข้อมูลเป็น Group Mean ± SE
sum_pct <- df_pct %>%
group_by(visit_clean, group) %>%
summarise(
ymean = mean(pct_change, na.rm = TRUE),
yse = sd(pct_change, na.rm = TRUE) / sqrt(n()),
.groups = "drop"
)
# 3. สร้างกราฟ
ggplot(sum_pct, aes(x = visit_clean, y = ymean, color = group, group = group)) +
# เส้นอ้างอิงที่ 0% (Baseline)
geom_hline(yintercept = 0, linetype = "dashed", color = "grey50") +
# เส้น Trajectory และ Error Bars
geom_line(size = 1.2) +
geom_errorbar(aes(ymin = ymean - yse, ymax = ymean + yse), width = 0.15) +
geom_point(size = 3, shape = 21, fill = "white", stroke = 1.5) +
# ปรับแต่งแกนและ Label ให้ตรงกับข้อมูลจริง
scale_color_manual(values = c("Supplement" = "#2E8B57", "Control" = "#CD5C5C")) +
scale_x_discrete(labels = c("M00" = "Baseline",
"M03" = "3 Months",
"M06" = "6 Months",
"M09" = "9 Months",
"M12" = "12 Months")) +
labs(
title = paste("% Change Trajectory:", ylab),
subtitle = "Calculated systematically from Day 0 | Mean ± SE",
x = "Timeline",
y = "% Change from Baseline",
color = "Study Group"
) +
theme_minimal() +
theme(legend.position = "bottom")
}
ส่วนที่ 1 คำนวณ % change
เราได้ทำการ filter() visit ที่เราต้องการจะเอามาวิเคราะห์ Trajectory Plot จากนั้นทำการ group ด้วย visit และ id ด้วย group_by() แล้วทำการเรียงข้อมูลจากน้อยไปหามาก โดยค่า default คือ Ascending Order จากนั้นทำการ mutate() หรือเพิ่ม column ชื่อ baseline_val และ pct_change ออกมา แล้วเราก็ปลอดซิปด้วย ungroup()
# 1. คำนวณ % change โดยการใช้สูตรดึงค่าวันแรก (M00) ของแต่ละ id
df_pct <- df_prepared %>%
filter(visit_clean %in% c("M00", "M03", "M06", "M09", "M12")) %>%
group_by(id, group) %>%
arrange(visit_clean) %>%
mutate(
baseline_val = first(.data[[var]]), ## .data[[var]] = df_prepared$var
# คำนวน % change โดยใช้สูตร
pct_change = ((.data[[var]] - baseline_val) / baseline_val) * 100
) %>%
ungroup()
Tidyverse ใช้ first() ซึ่งต้อง arrange() ก่อนเสมอ 🤯
ส่วนที่ 2 summay ข้อมูลด้วย mean ± SE หลังจากที่เราได้ percent loss ของแต่ละ feature มาแล้ว เอามารวมเพื่อสรุปเป็นข้อมูลที่ได้ของแต่ละ group (control vs supplement)
# 2. สรุปข้อมูลเป็น Group Mean ± SE
sum_pct <- df_pct %>%
group_by(visit_clean, group) %>%
summarise(
ymean = mean(pct_change, na.rm = TRUE),
yse = sd(pct_change, na.rm = TRUE) / sqrt(n()),
.groups = "drop"
)
ส่วนที่ 3 summary ข้อมูลด้วย mean ± SE 3.1 โครงสร้างของ ggplot ⭐️ ggplot2 สร้างกราฟแบบ Layer by Layer ทับกันทีละชั้น เหมือนวาดรูปบน Canvas จะเป็นส่วนของ Data visualization โดยการนำข้อมูลจาก sum_pct %>% ลงมา plot เป็นกราฟเส้น geom_line โดยแกน x เป็นข้อมูลของ visit date ที่เราต้องการ และ แกน y คือ mean ค่าเฉลี่ย % change ของ parameter นั้นๆ ในส่วนของ color = group เป็นการแยกสีตามกลุ่ม
# 3. สร้างกราฟ
ggplot(sum_pct, aes(x = visit_clean, y = ymean, color = group, group = group)) +
# เส้นอ้างอิงที่ 0% (Baseline)
geom_hline(yintercept = 0, linetype = "dashed", color = "grey50") +
# เส้น Trajectory และ Error Bars
geom_line(size = 1.2) +
geom_errorbar(aes(ymin = ymean - yse, ymax = ymean + yse), width = 0.15) +
geom_point(size = 3, shape = 21, fill = "white", stroke = 1.5) +
# ปรับแต่งแกนและ Label ให้ตรงกับข้อมูลจริง
scale_color_manual(values = c("Supplement" = "#2E8B57", "Control" = "#CD5C5C")) +
scale_x_discrete(labels = c("M00" = "Baseline",
"M03" = "3 Months",
"M06" = "6 Months",
"M09" = "9 Months",
"M12" = "12 Months")) +
labs(
title = paste("% Change Trajectory:", ylab),
subtitle = "Calculated systematically from Day 0 | Mean ± SE",
x = "Timeline",
y = "% Change from Baseline",
color = "Study Group"
) +
theme_minimal() +
theme(legend.position = "bottom")
}
ส่วนของ geom นั้น เราจะเปรียบเสมือน templete ของสิ่งที่เราอยากจะสร้างมันออกมา จาก code ส่วนที่ 3 นั้น เรามี geom ดังนี้
geom_hline(yintercept = 0, linetype = "dashed", color = "grey50") +
# เส้น Trajectory และ Error Bars
geom_line(size = 1.2) +
geom_errorbar(aes(ymin = ymean - yse, ymax = ymean + yse), width = 0.15) +
geom_point(size = 3, shape = 21, fill = "white", stroke = 1.5)
⭐️ การใช้ patchwork เพื่อให้แสดงภาพทุกภาพในครั้งเดียว !!
- เป็น library ที่ใช้สำหรับรวมกราฟใน ggplot2 ให้อยู่ในภาพเดียวกัน โดยใช้เครื่องหมาย + , | , / ในการจัดการ layer ของรูปภาพ
😆👍🏻 การใช้ library(patchwork) + การเอา control flow มาช่วยในการเรียกใช้ funtion ซ้ำๆ ได้เลย (100 graph ทำได้ใน click เดียว)
เตรียมข้อมูลที่จะเอาเข้าไปวิ่งใน loop ก่อนว่าเราจะเอาตัวแปรไหนบ้าง ? ถ้าให้วิ่งไปเอาทุก column จะใช้อีกแบบหนึ่ง แต่จะดูยุ่งเยิงไป code ที่ดีต้องอ่านง่าย simple but effective ใครมาดูก็สามารถอ่านและนำไปปรับใช้ได้
params <- list(
list(var = "weight_kg", ylab = "Weight Loss (kg)"),
list(var = "body_fat_pct", ylab = "BodyFat (%)"),
list(var = "lean_kg", ylab = "Muscle Lean (kg)"),
list(var = "bmr", ylab = "BMR"),
list(var = "hb_a1c", ylab = "HbA1C"),
list(var = "ldl", ylab = "Low-density Lipoprotein (LDL)"),
list(var = "bmi", ylab = "BMI (kg/m2)")
)
- ส่วนการสร้างกราฟแบบอัตโนมัติด้วย function lapply ซึ่งทำหน้าที่เป็น loop วิ่งไปแต่ละ params ที่เราเตรียมเอาไว้ด้านบน
plots <- lapply(params, function(p) {
plot_trajectory_pct(p$var, p$ylab)
})
- การจัด layout และรวมกราฟ (patchwork) และทำการ wrap ให้มาอยู่ในภาพเดียวกัน
wrap_plots(plots, ncol = 2) + ## 2 column
plot_annotation(
title = "% Change Trajectory — All Parameters",
subtitle = "Mean ± SE | Supplement vs Control",
theme = theme(plot.title = element_text(size = 16, face = "bold"))
)
wrap_plots(plots, ncol = 2) +
plot_layout(guides = "collect") + # auto, collect, keep
plot_annotation(title = "% Change Trajectory — All Parameters") &
theme(legend.position = "bottom")
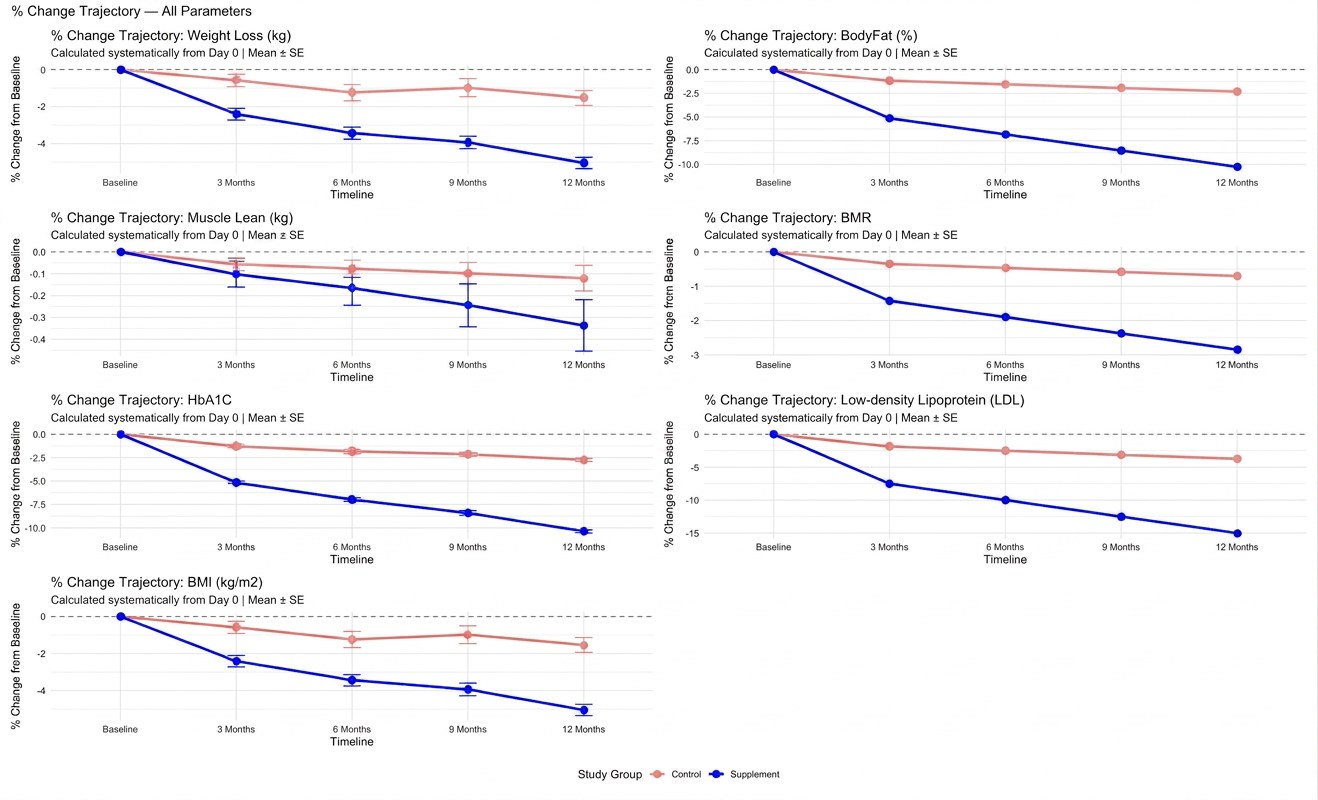 fig 4: Mean±se percentage change over a 90-day trajectory: Supplement compared with control all parameters.
fig 4: Mean±se percentage change over a 90-day trajectory: Supplement compared with control all parameters.
จากผลการวิเคราะห์จะเห็นว่าทุกๆ parameter หลังจากผ่านไป 12 เดือนพบว่า supplement มี trend ลดลงมากกว่าในกลุ่ม control อย่างเห็นได้ชัด และเส้น control ดูไม่ได้ห่างจากเดิมมากเท่าที่ควร (เส้นอ้างอิง) แปลว่าผลลัพธ์ได้ไม่ดีเท่า supplement
เป็นยังไงกันบ้างงกับ part 101 จริงๆ จะต่อ stat อีกนิดแต่ไม่ไหวแล้ววววววว 5555555 ไว้มาต่อ Part 102 กันน๊าาาาาา 1594 word is amazing !! 😎 ใครอดใจไม่ไหวแล้ว อยากไปดูต่อว่า Ruby's Duckie สุดที่ตรงไหนนน ไปตามต่อได้ใน Ruby's Duckie
Comments